
Spring Data JPA 快速入门
Spring Data JPA 快速入门
目标: 了解如何使用Spring Data JPA从数据库中存储和检索数据。
参考:
介绍
Spring Data JPA是一个功能强大的框架,允许用户轻松地与数据库交互,同时最大限度地减少样板代码。 在本教程中,我们将研究如何使用Spring Data JPA插入数据库并从数据库查询数据。 我们将使用IntelliJ IDEA Ultimate创建一个简单的Spring靴子应用程序,以利用其Spring特性支持。
创建一个新的Spring Boot项目
首先,在 IntelliJ IDEA Ultimate 中,我们将通过在欢迎屏幕中点击 "New Project" 来创建一个新项目。 我们将从左侧菜单中选择 "Spring Initializr"。然后,我们将指定项目的名称 - 你可以将其命名为 SpringDataJPA。 我们还可以将 "Group" 字段更改为我们公司的名称。 对于其余的字段,你可以接受默认值。请随意为你的项目使用最新的 Java 版本。
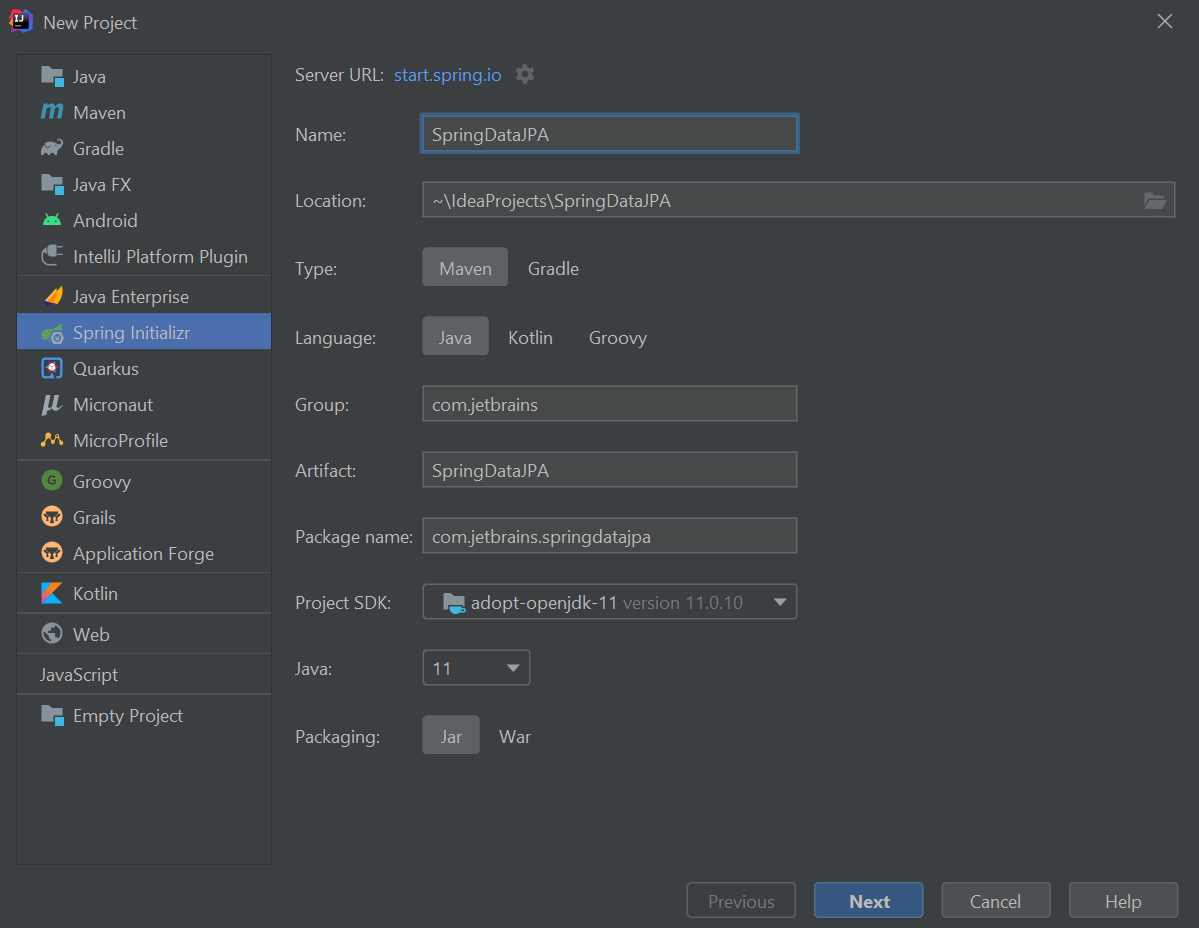
接下来,我们将点击 "Next"。
在接下来的窗口中,我们将选择我们可用的最新的 Spring Boot 版本。 然后在 "Dependencies" 下,我们将在搜索框中搜索 "data"。 在 SQL 下,我们将从列表中选择 Spring Data JPA 和 H2 Database 的复选框。 对于本教程,我们将使用 H2 作为我们的数据库,因为它很容易设置。 如果你想使用不同的数据库,比如 MySQL 或 HyperSQL,可以随意选择这些依赖项,或者稍后将它们添加到你的 pom.xml 文件中。
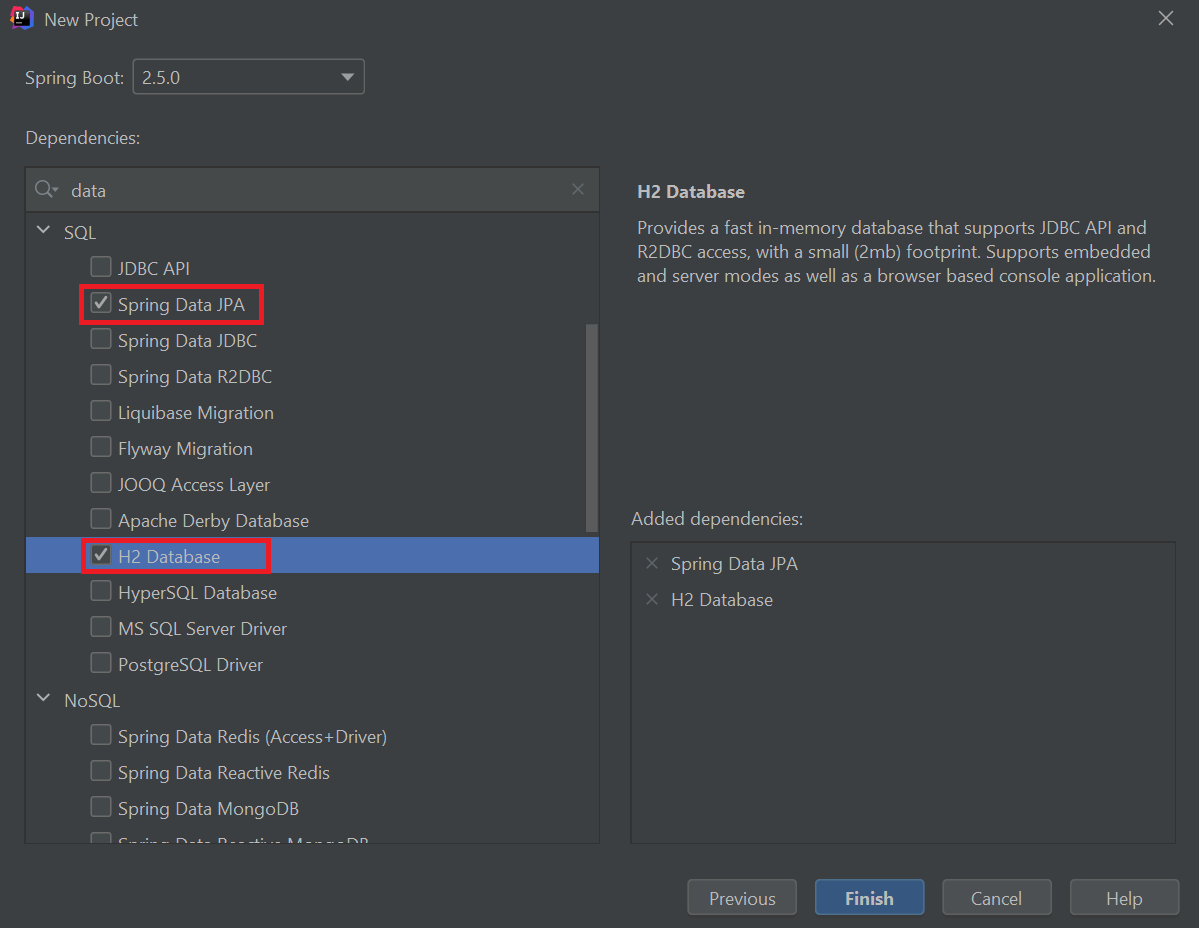
一旦我们点击 "Finish",IntelliJ IDEA 就会创建一个带有 Spring Data JPA 和数据库依赖的新的 Spring Boot 项目。
创建员工实体
实体是一个Java类,代表着你想要插入到数据库中的数据。 对于我们的应用程序,我们将创建一个名为 Employee 的实体, 我们将使用它来将员工数据插入到我们数据库中的 Employee 表中。
在项目工具窗口中,我们将导航到我们的 src/main/java 目录,选择 com.jetbrains.springdatajpaapp 包, 并按下 ⌘N (macOS) / Alt+Insert (Windows/Linux)。选择 Java Class,然后输入我们的实体名称 - Employee。 然后,按下 ⏎ (macOS) / Enter (Windows/Linux)。
在 Employee 类中,我们将通过在类定义中添加 @Entity 注解并导入 javax.persistence.Entity 包来将其设置为实体。 一旦你这样做了,你会注意到你的类中出现了一个错误。
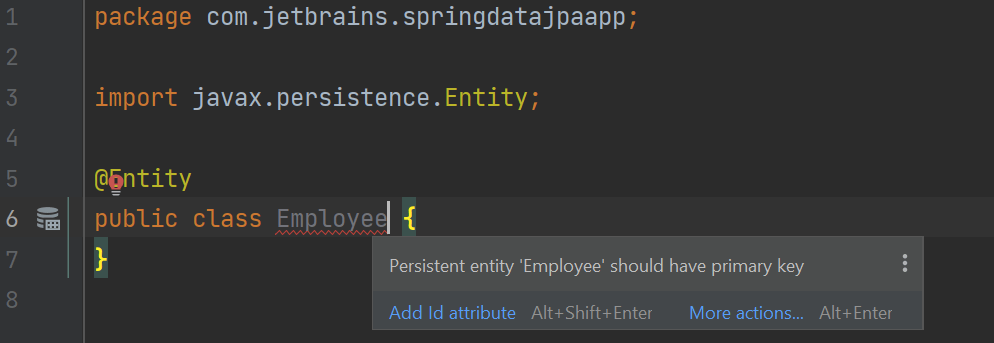
正如错误消息所指示的,实体必须有一个由 @Id 注解指定的主键字段。我们将使用 ⌥⏎ (macOS) / Alt+Enter (Windows/Linux) 快捷键, 这样 IntelliJ IDEA 就可以为我们添加 ID,这将导致提示输入 ID 字段的信息。 我们将采用默认的名称和类型。 你可以选择 "Field Access" 复选框(我更喜欢在字段上使用注解,而不是在 setter 方法上,因为我觉得这样更易读)。 你也可以选择 "Generated" 复选框,这样你就不必自己分配员工 ID。
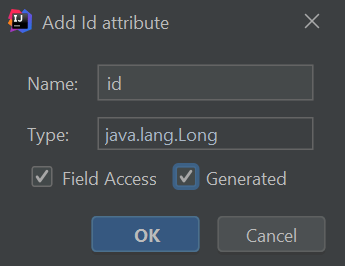
然后,我们将点击 "OK"。你会注意到 IntelliJ IDEA 创建了一个带有其 setter 和 getter 的 id 字段。
接下来,让我们添加几个 String 字段:firstName 和 lastName。
接下来,我们将通过调出 Generate 菜单 ⌘N (macOS) / Alt+Insert (Windows/Linux),然后选择 Constructor 来生成我们的构造函数。 我们不需要构造函数接收一个 id,因为我们的 id 将会自动生成, 所以我们将点击 firstName,然后按住 ⌘ (macOS) / Ctrl (Windows/Linux) 键,然后选择 lastName。
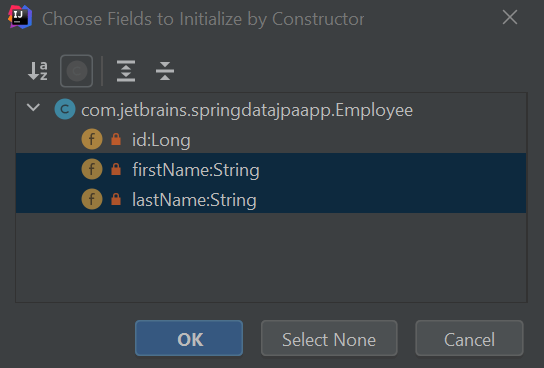
然后,我们将点击 "OK"。
你现在会注意到你的 Employee 类上出现了一个错误,因为你没有一个无参构造函数。 如果你在错误上按下 Alt+Enter (Windows/Linux) 或 ⌥⏎ (macOS),IntelliJ IDEA 将为你提供创建它的选项 - 让我们继续执行。
接下来,我们将生成字段的 setter 和 getter。 我们将调出 Generate 菜单 ⌘N (macOS) / Alt+Insert (Windows/Linux),然后选择 Getter 和 Setter。 我们将按住 ⌘ (macOS) / Ctrl (Windows/Linux) 键,并选择两个变量。 然后,我们将点击 "OK"。IntelliJ IDEA 为这两个变量生成了 getter 和 setter。
最后,让我们再次调出 Generate 菜单 ⌘N (macOS) / Alt+Insert (Windows/Linux),然后选择 toString 来生成一个 toString 方法。 我们将保持所有字段选中,然后点击 "OK"。
最终,Employee 实体应该类似于以下内容(格式可能会有所不同):
package com.jetbrains.springdatajpaapp;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
@Entity
public class Employee {
@Id @GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
private String firstName;
private String lastName;
public Employee() {
}
public Employee(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
public void setId(Long id) {
this.id = id;
}
public Long getId() {
return id;
}
public String getFirstName() {
return firstName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
@Override
public String toString() {
return "Employee{" +
"id=" + id +
", firstName='" + firstName + '\'' +
", lastName='" + lastName + '\'' +
'}';
}
}
创建 Repository 接口
现在我们已经创建了 Employee 实体,我们需要一种方式来执行 CRUD(创建、读取、更新、删除)操作。 幸运的是,Spring Data JPA 通过 Repositories 提供了所有基本的操作。让我们看看它们是如何工作的。
在项目工具窗口中,我们将选择 com.jetbrains.springdatajpaapp 包,并按下 ⌘N (macOS) / Alt+Insert (Windows/Linux)。 选择 Java Class。 我们将其命名为 EmployeeRepository,这次我们选择 Interface 然后按下 ⏎ (macOS) / Enter (Windows/Linux)。 为了使我们的接口成为一个 repository,我们需要让它扩展 CrudRespository<T, ID> 接口,其中泛型参数是我们的实体类和实体的 id 类型。 所以对于我们的应用程序,我们的 repository 接口定义将会是:public interface EmployeeRepository extends CrudRepository<Employee, Long>。
我们将使用这个 EmployeeRepository 接口来在我们的应用程序代码中执行 CRUD 操作。 由于我们正在扩展 CrudRepository,我们默认就可以访问基本的 CRUD 方法。 例如,我们可以调用 save 方法将一个 Employee 对象插入到我们的数据库中。 我们也可以调用 findAll 方法来列出你的 Employee 表中的所有员工。 当我们编写我们的应用程序逻辑时,我们将看到如何做到这一点。
在大多数应用程序中,你会发现自己希望做的事情超出了 CrudRepository 接口默认提供的范围。 例如,假设我们想要找到所有姓氏中包含空格的员工。你当然可以编写一个 SQL 查询来实现这个功能。 然而,一个更简单的方法是利用 Spring Data JPA,它允许你在你的 repository 中创建方法,这些方法将根据方法名被转换为查询。
例如,假设我们想要添加一个方法来查找所有姓氏中包含特定字符串的员工。 我们将前往我们的 EmployeeRepository 接口,并开始声明我们的方法。 我的方法将返回一个员工列表,因此我们将使用 List<Employee> 作为返回类型。 然后,我们需要指定一个由两部分组成的方法名:引入部分和条件部分。 我们可以在 IntelliJ IDEA 中使用 ⌃␣ (macOS) / Ctrl+Space (Windows/Linux) 来查看引入部分的方法建议列表:
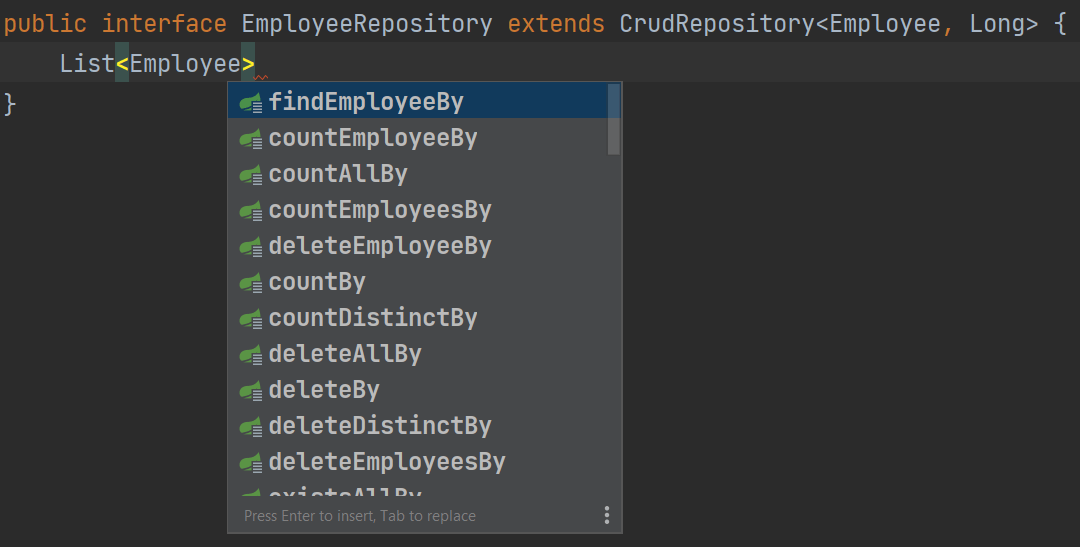
我们将选择 findEmployeesBy 作为引入部分。 然后,我们将再次点击 ⌃␣ (macOS) / Ctrl+Space (Windows/Linux) 来查看可以选择的条件列表。
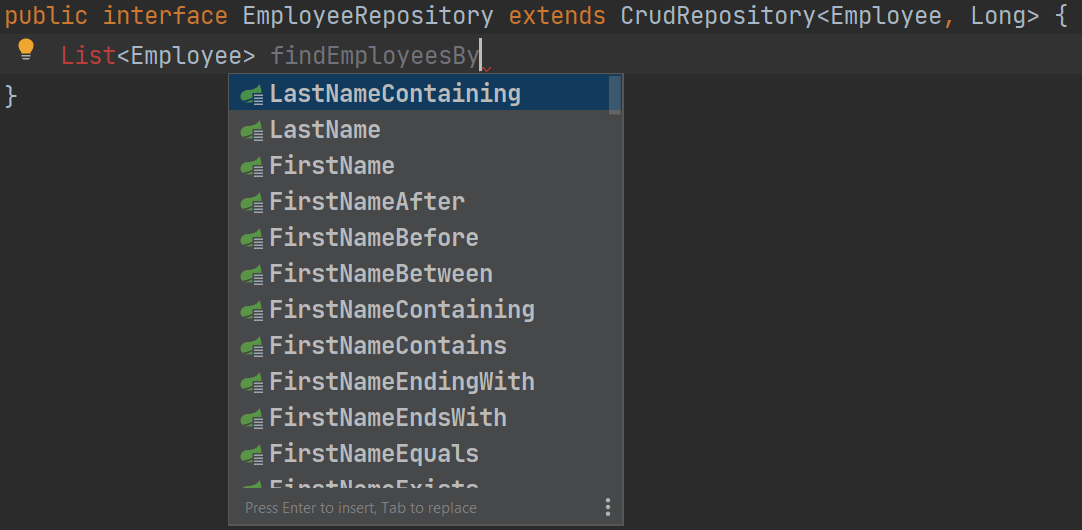
我们将选择 LastNameContaining。最后,我们将声明一个 String 方法参数,表示我们要检查的字符串。 现在我们有了一个方法,可以找到所有姓氏中包含所提供字符串的员工。
你可能会想:如果我定义了这个接口,我不是必须要实现它吗?答案是否定的。 Spring Data JPA 会为你处理这些!你只需要定义你的 Repository 接口,并遵循 Spring Data 的约定声明你的方法。 当你添加更多方法时,如果在方法名中犯错,IntelliJ IDEA 将会指出错误。 例如,如果我们尝试创建一个用于查询具有不正确 LName 属性的员工的方法,IntelliJ IDEA 会给出一个错误,说Cannot resolve property LName。
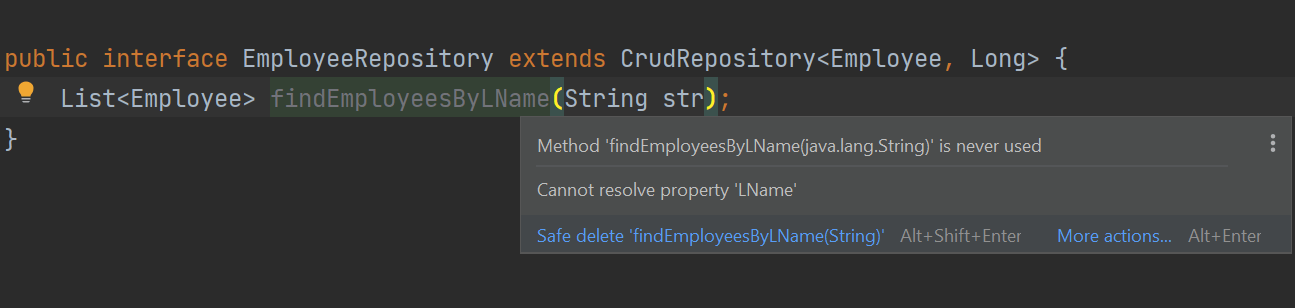
最终,你的 EmployeeRepository 接口应该如下所示:
package com.jetbrains.springdatajpaapp;
import org.springframework.data.repository.CrudRepository;
import java.util.List;
public interface EmployeeRepository extends CrudRepository<Employee, Long> {
List<Employee> findEmployeesByLastNameContaining(String str);
}
配置数据库
此时,我们可以使用 Spring Boot 为我们创建的默认内存数据库。 然而,默认数据库功能有限,并且在应用程序终止后不允许数据保留,因此让我们继续配置一个数据库。
我们将调出搜索菜单 ⇧⇧ (macOS) / Shift+Shift (Windows/Linux) 并搜索我们的 application.properties 文件。 在我们的 application.properties 文件中,我们可以利用 IntelliJ IDEA 的建议来指定连接到我们的 H2 数据库所需的属性。 我们将开始输入 url,并从建议列表中选择 spring.datasource.url 属性。
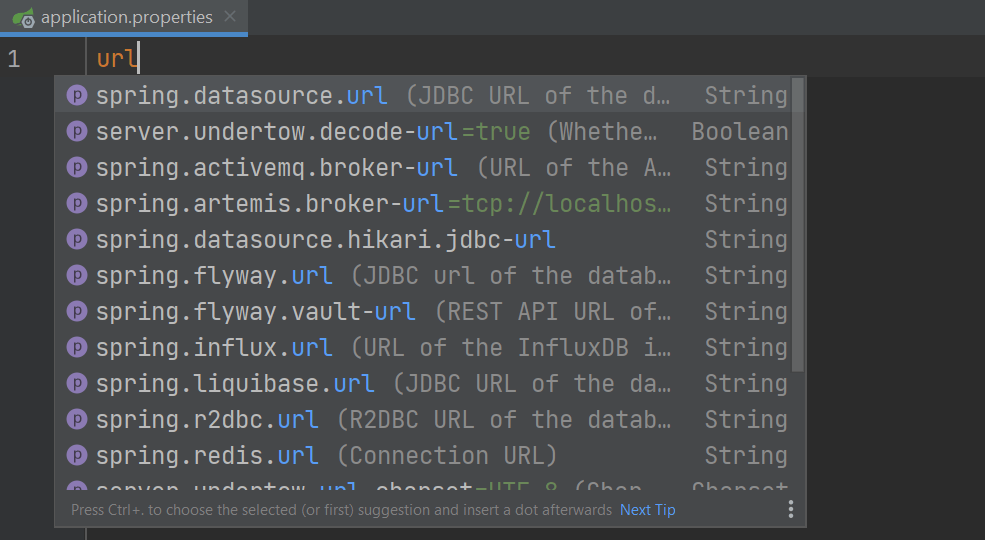
如果你没有使用 H2 作为你的数据库,你可以在这里指定你自己的数据库 URL。 在我们的情况下,我们将指定 jdbc:h2:file:./data/myDB 作为我们的 URL,这将创建一个名为 myDB 的 H2 数据库。
接下来,我们需要指定我们的驱动类名。 我们可以类似地搜索 driver,并从我们的建议列表中选择 spring.datasource.driver-class-name。 一旦我们选择了这个,IntelliJ IDEA 将根据我们之前指定的 URL 提供 H2 驱动程序的建议值,因此我们可以选择它。
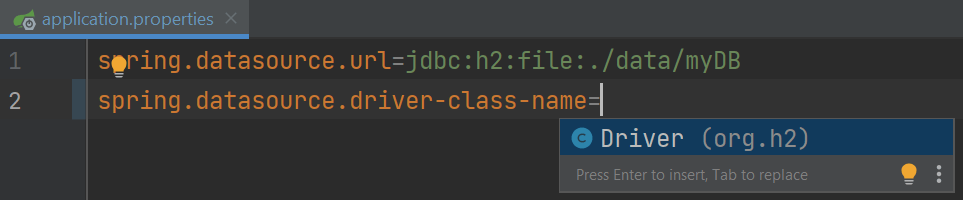
接下来,我们同样搜索 username 和 password 属性,并将它们的值分别设置为 sa 和 password。
最后,我们不想手动创建任何表,因此我们将添加 spring.jpa.hibernate.ddl-auto 属性,并使用代码完成来查看可能的值列表。
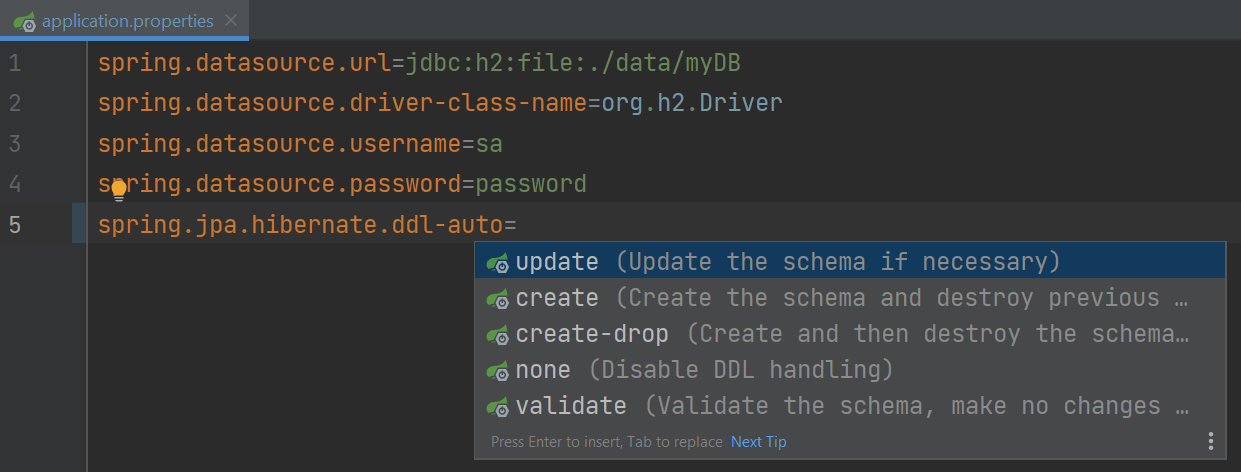
对于我的应用程序,我将把属性值设置为 update,这样如果表不存在,它将在数据库中创建表,并在我对实体进行更改时更新它们。
最终,你的 application.properties 文件应该如下所示:
spring.datasource.url=jdbc:h2:file:./data/myDB
spring.datasource.driver-class-name=org.h2.Driver
spring.datasource.username=sa
spring.datasource.password=password
spring.jpa.hibernate.ddl-auto=update
从应用程序写入数据库
现在我们有了我们的 Employee 实体、Repository 和数据库配置,我们准备编写我们的应用程序逻辑。 假设我们想要向我们的数据库插入四个员工。我们将导航到为我们的 Spring Boot 应用程序 创建的 SpringDataJpaApplication 类 ⇧⇧ (macOS) / Shift+Shift (Windows/Linux)。
练习:
花几分钟时间看看你能否创建一个 insertFourEmployees(EmployeeRepository repository) 方法,使用 save() 方法插入员工。
完成了吗?以下是你的方法应该是什么样子的:
private void insertFourEmployees(EmployeeRepository repository) {
repository.save(new Employee("Dalia", "Abo Sheasha"));
repository.save(new Employee("Trisha", "Gee"));
repository.save(new Employee("Helen", "Scott"));
repository.save(new Employee("Mala", "Gupta"));
}
现在,让我们继续在我们的应用程序中调用那个方法。在一个典型的 Spring Boot 应用程序中,我们会有一个服务类,其中包含服务提供的功能。 然而,由于我们只是做一些一次性的操作,让我们保持简单,使用一个 Bean 来调用我们的 insertFourEmployees 方法。 然后,让我们调用 repository.findAll() 来检索已插入的实体。下面是代码示例:
@Bean
public CommandLineRunner run(EmployeeRepository repository) {
return (args) -> {
insertFourEmployees(repository);
System.out.println(repository.findAll());
};
}
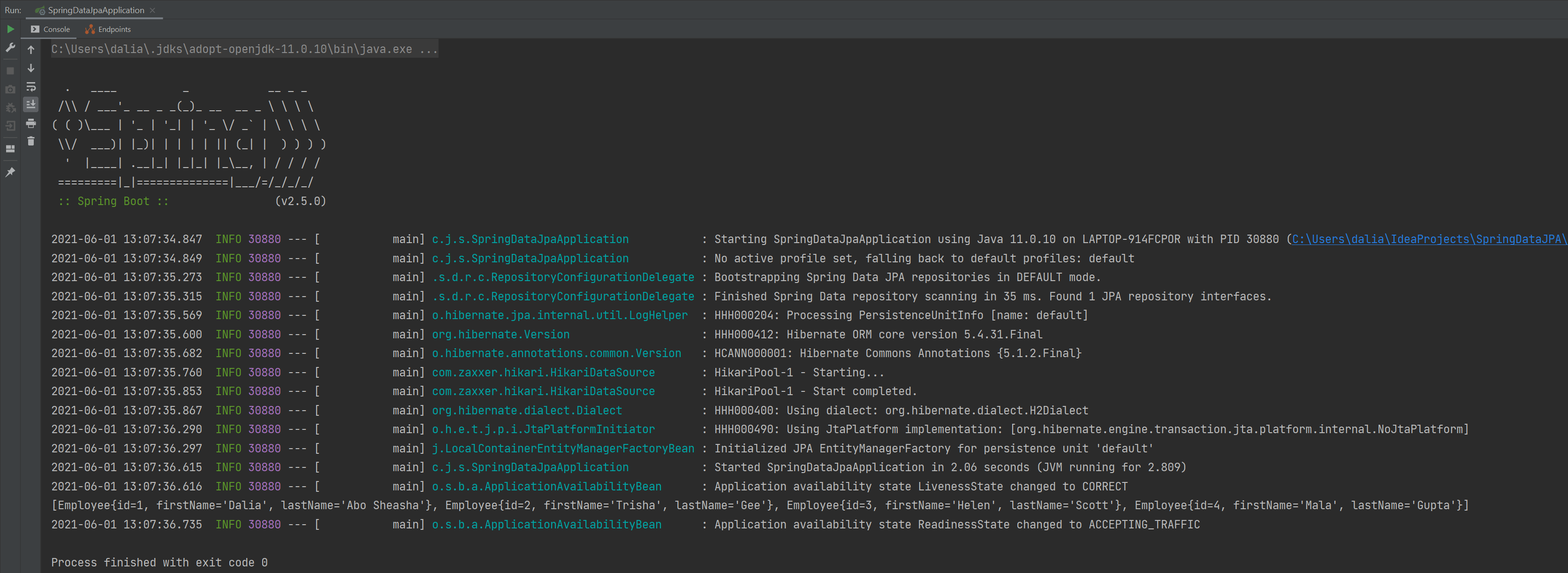
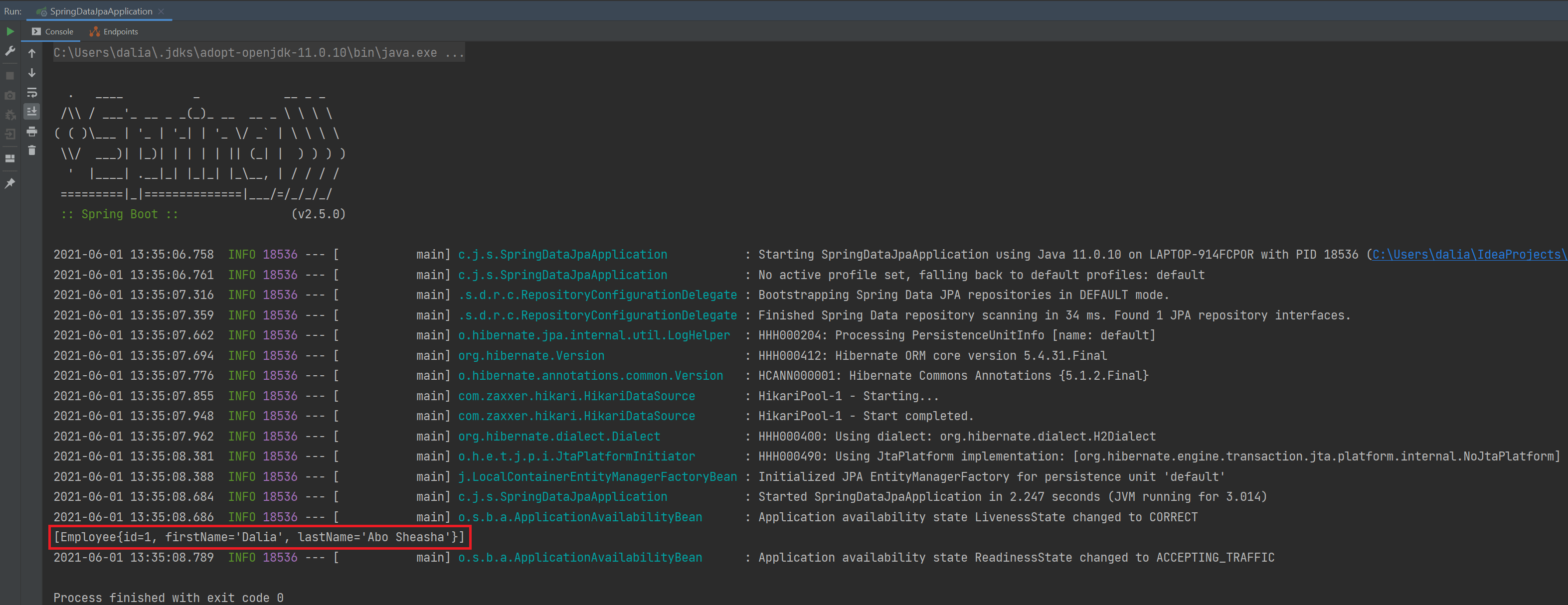
让我们运行我们的应用程序并看到它的运行情况。我们将按 ⌃R (macOS) / Shift+F10 (Windows/Linux)。
最终结果,一旦我们的应用程序启动,我们可以看到控制台日志显示我们的 Spring Boot 应用程序正在启动。 然后,我们可以看到 findAll 调用的结果,打印出数据库中所有的员工。
创建数据源
在你的项目中使用数据库时,在IntelliJ IDEA中创建一个数据源连接非常有用。 它允许你在IDE中轻松地与数据库进行交互。让我们为我们的H2数据库创建一个数据源连接。 如果你正在使用其他数据库,你可以使用类似的步骤,或者你可以按照 IntelliJ IDEA数据库连接帮助页面中概述的说明进行操作。 请注意,此功能仅适用于IntelliJ IDEA Ultimate版。
要创建我们的H2数据源,我们将打开数据库工具窗口(View | Tool Windows | Database),然后点击+按钮。 有多种方式可以创建我们的连接。我们将使用Data source from URL选项。
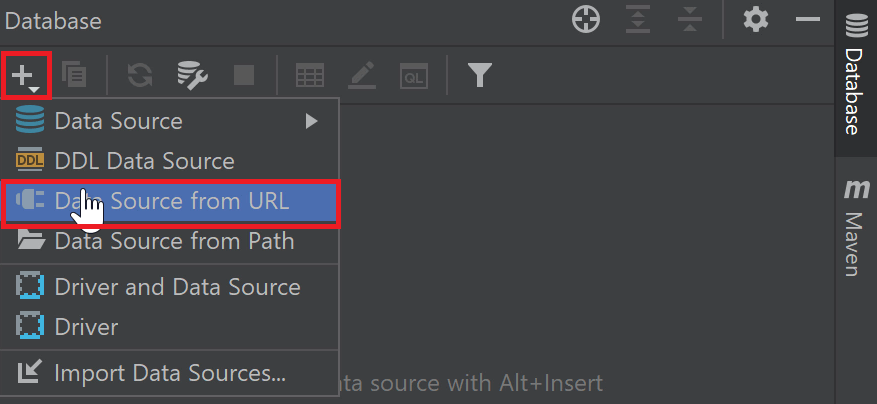
我们将输入我们的数据库URL:jdbc:h2:file:./data/myDB,然后点击确定。
接下来,我们将完成数据库的配置。对于我们的用户和密码字段, 我们将输入在我们的application.properties文件中设置的用户和密码(sa,password)。 如果你收到有关缺少H2驱动程序的警告,请点击下载缺失的驱动程序文件。
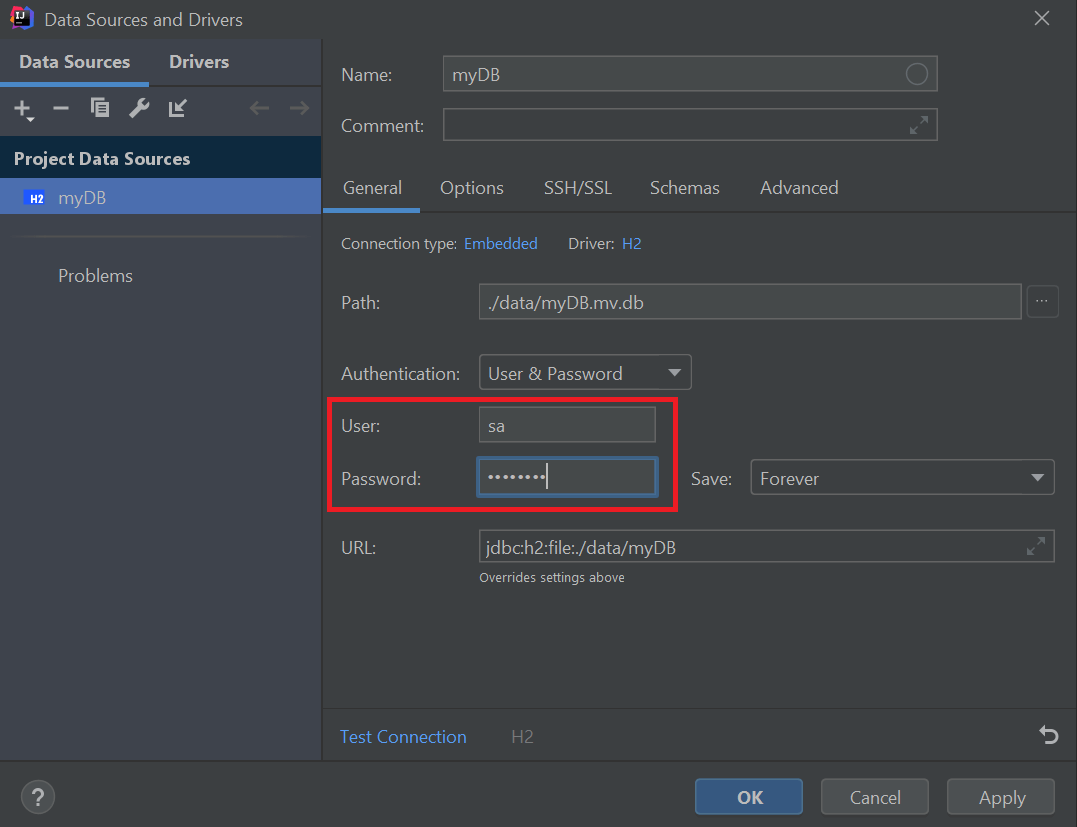
可选步骤:在选项选项卡下,启用“设置后自动断开连接”,并将其设置为在3秒后断开连接。 此设置将断开IntelliJ IDEA中的数据库并释放所有锁定,使我们应用程序的进程可以持续连接并写入数据库。 这将防止来自你的应用程序的database may already be in use的错误。 如果执行了此步骤,则可能需要在数据库工具窗口中点击“刷新”按钮以更新数据源。
然后,我们将点击“Test Connection”以确保我们的配置是有效的。
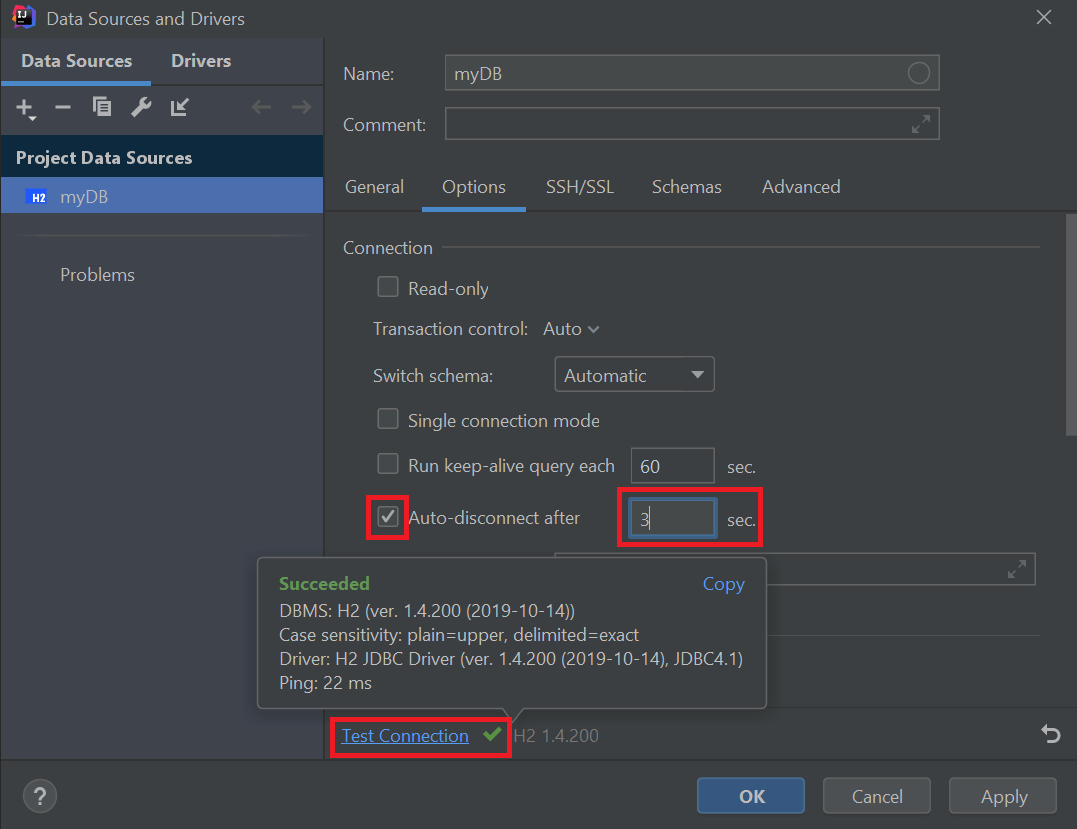
一旦我们点击"OK",我们就会看到一个新的数据源,用于我们的H2数据库。
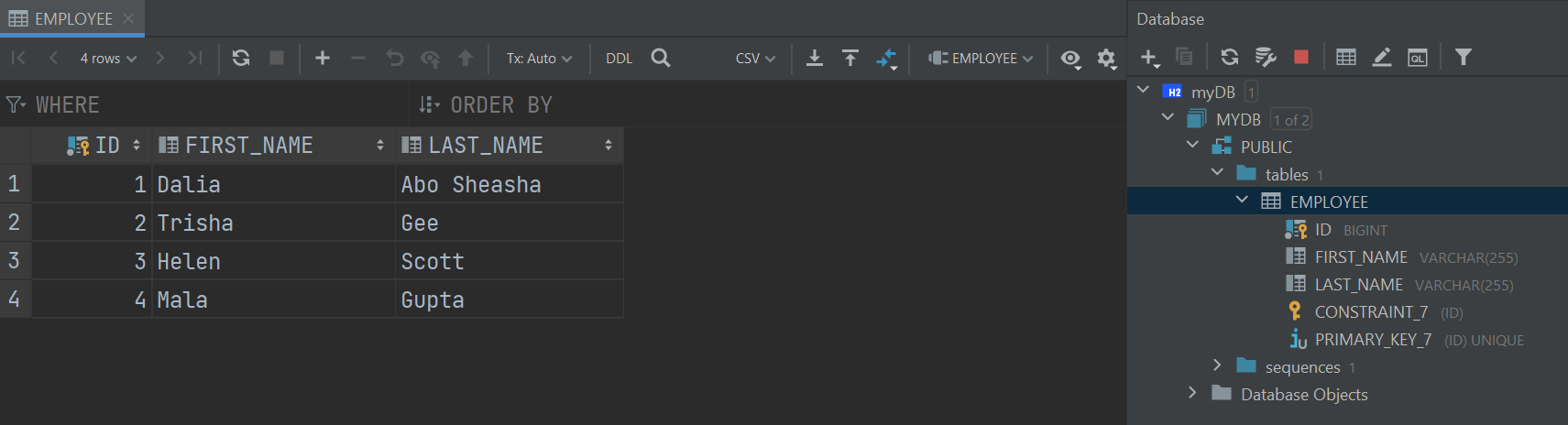
最终结果 ,在数据库视图中,我们现在可以导航到我们的Employee表,并通过双击表格查看所有员工数据。
调用自定义查询
假设我们想要查询数据库中所有姓氏中包含空格的员工。
练习:花几分钟时间编写代码,查找并打印姓氏中带有空格的所有员工。
完成了吗?以下是实现代码的样子:
@Bean
public CommandLineRunner run(EmployeeRepository repository) {
return (args) -> {
System.out.println(repository.findEmployeesByLastNameContaining(" "));
};
}
最终结果, 如果你插入了教程中提到的相同数据,你应该在控制台输出中看到"Dalia"员工。
总结
在这个教程中,我们创建了一个简单的Spring Boot应用程序,它使用Spring Data JPA来存储和检索数据库中的数据。
一些在教程中提到的有用的快捷方式包括:
| Name | Windows Shortcut | macOS Shortcut |
|---|---|---|
| 创建类并生成构造函数/方法 | Alt+Insert | ⌘N |
| 上下文感知代码完成 | Ctrl+Space | ⌃Space |
| 到处搜索 | Shift+Shift | Shift+Shift |
| 运行你的应用程序 | Shift+F10 | ⌃R |
你可以在这个GitHub仓库中找到通过这个教程创建的最终项目。
帮助链接
- Spring.io: Spring Data JPA
- Spring Guide: Accessing Data with JPA
- Working with Hibernate/JPA in IntelliJ IDEA (2021) (video)
- (documentation) Spring Support in IntelliJ IDEA
- (documentation) Explore Spring support features
- (documentation) Database Connection in IntelliJ IDEA
- (video) Getting started with Spring Data JPA